SillyTavern presets. The lifeline. Unfortunately, there’s really no clean way to “do” a SillyTavern preset comparison. It’s made more difficult by the fact that you can’t really see output side-by-side, so you’d have to swap around and mess around just to see the output a preset can give you. On top of that, the good community presets are often discussed, but that leaves little spotlight for the other smaller presets the community worked hard on. Those get little to no discussion.
With no quick, braindead way to see the contents of a preset, no way to run the same prompt through two presets at once, no central list for presets, I decided to try something out. So I made PresetLab.
SillyTavern weekly news for the week of June 16 to June 22, 2026. The model story this week is still GLM 5.2 *yawn* (kidding, I’m just salty from z.AI’s shift). Putting that to the side, the real story is the user-side tooling cluster: DeepLore v2.5, Natural Extended v0.9, Leonardo, Zebede, and a quiet but real character-card workflow shift. Megumin V8. GitHub quiet. Also, what model is Owl Alpha on OR?.. That’s not part of the news. That’s my personal question. Stealth models drive me nuts.
SillyTavern weekly news. We’re going to ignore that there was no SillyTavern weekly news for the entire month of May. Or any post, really (Did I say I was sorry?)
The SillyTavern weekly news of June 8 to 15, 2026 was a model release week, which is also the only kind of week that matters around here. *GLM 5.2* finally hit OpenRouter, a few days late but no less hyped for the wait. *DeepSeek v4* turned out to be, against all odds, actually good. *Fable 5* launched and immediately started a culture war. Anthropic put new safeguards on old models in the kind of move that makes you check the date twice. And underneath it all, the SillyTavern GitHub ship sat quiet for the sixth week running.
It’s been a minute. Or two. Or technically closer to a couple of months, if we’re counting the calendar instead of pretending (and I’m good at pretending. That’s what RP is all about.)
I didn’t disappear on purpose. I just kept picking up one more thing, then one more thing after that, and somewhere between “I’ll write the post next weekend” and now, the next weekend stopped coming back around. So. Here we are. I’m back, briefly, to admit that I went dark and to promise there’s actually a reason for it. GLM vs MiniMax for RP
SillyTavern weekly news: Seven days of morning briefings compiled so you don’t have to scroll Reddit at 4am. You’re welcome.
The SillyTavern weekly news of April 20 to 27, 2026 was a big one if you live and breathe model releases and community drama. DeepSeek V4 dropped with a flashier little brother. Z.AI kept everyone in a permanent state of confusion about whether their legacy coding plans were about to get gutted. Kimi K2.6 launched and divided the room like every Kimi release does. And underneath all the noise, the SillyTavern GitHub ship stayed steady with critical bug fixes and a shiny new model on the approved list.
I moved off GLM. For anyone who’s been following along, that probably lands like a small betrayal. GLM was my go-to for a long time. It’s the model I built the article on Stab’s Directive Hierarchy around. I said I was a GLM simp in that article, and I meant it.
I’m not including my own tools/extensions here. This list showcases community extensions built by their incredible developers.
The Curse of Choices
Choices are a good thing, and choices are beyond plentiful in the world of SillyTavern extensions! The best SillyTavern extensions 2026 has to offer a new user is staggering. This is a fast-growing community, with a ton of helpful plugins out there. That being said, the resources for these kinds of things are a bit slim. They’re mostly relegated to the odd reddit post or some other corner of the internet (which is the whole reason I started RP|Fiend in the first place). So I thought it would be beneficial to do a little round-up of some extensions I found very useful. I may have already written an article on them, which I’ll link accordingly if you want to read more. Also, keep in mind that this is a list of extensions I’ve personally tried. If one of your extensions isn’t listed here, it doesn’t make it any less incredible or useful! Without further ado, let’s jump right into the best SillyTavern extensions 2026 has!
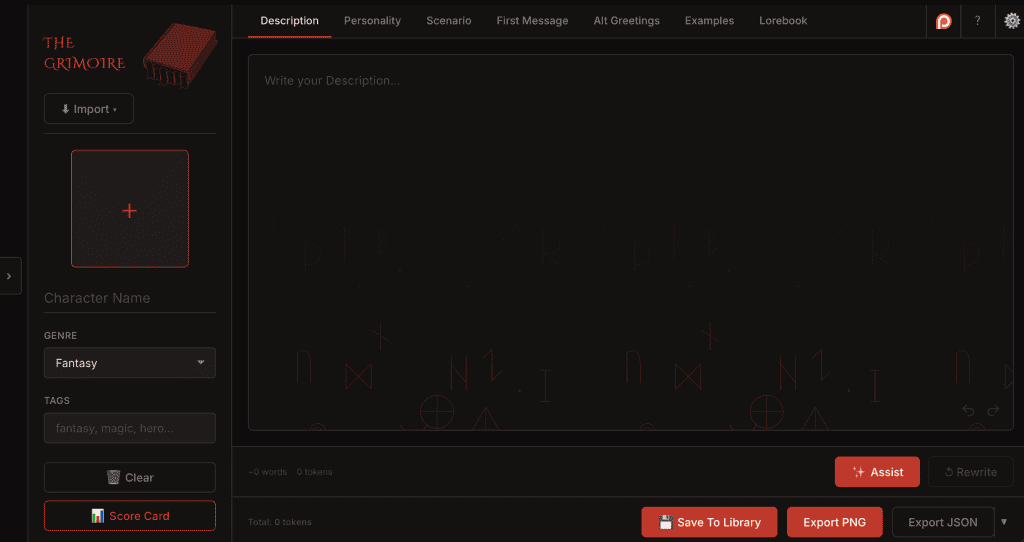
So, here I am again. I find it somewhat inconvenient to build new character cards. Most platforms have a built-in editor, and some of them don’t. As a full-time simpleton, I need something easy to use, convenient, and full-featured. Most importantly, NOT tied to a platform. There’s plenty of AI character card tools out there, but I, (yours truly), decided to take a jab at it, as I found them a little lacking in some of the features I was seeking. As such, I am pleased to present you with…
The Grimoire!
What is The Grimoire, exactly?.. I shan’t conceal it any longer!
What Is It?! Another AI Character Card Editor?!
..Ahem. The Grimoire is a free (free indeed!), browser-based AI character card editor I made. So no downloading, no installing, and nothing to setup or configure. It’s designed to be field by field, iteratively, with structure.
It supports V3 spec and exports both PNG and JSON, so don’t worry about what platform you’re using. As long as it’s able to read a standard-format character card, you’re golden. It’s not designed to be just a SillyTavern character card editor, even if that is my primary platform.
I designed it to be less of a generator, and more like a proper authoring environment. Character cards can be a personal thing, and I think that’s cool. I wanted the AI to actually assist, not takeover. Hence, any prompts sent are context-aware; factoring and inferring from the information you’ve already provided in other fields. It’s a pretty complete AI character card tool, with more planned.
Introducing a SillyTavern Lorebook Extension – Scribe!
Scribe is a personal little project I’ve been working on for a while. A SillyTavern lorebook extension for lazy people. I’m notoriously lazy. So much so that even when I use something like WorldInfo Recommender (which is great, by the way. Check my article on it here!), I still find myself too lazy to stop the story, open a menu, enter a prompt, and generate an entry. So I thought “Man, wouldn’t it be great to highlight a specific name, place, or entity, and simply make a lorebook entry without even having to open a menu?”. So I made Scribe! A lorebook editor that allows you to simply highlight text and create/update a lorebook entry.
How It Works
Scribe was designed for dummies, by a dummy. So it’s painfully simple to use. Listen up, dummy!
I realize now after writing a few guides on SillyTavern that I never made one of the more important ones: Getting the damned thing up and running. Luckily, SillyTavern is supported among all operating systems (even Android, although that IS Linux-based but won’t be covered here). This is meant to be a catch-all, simple guide on how to install SillyTavern on any platform ya got. Without further dribble, let’s begin!
Requirements (The Boring Part)
Windows: Windows 10 or 11 (64-bit, and no Vista pls)
Mac: macOS 12 Monterey or later
Linux: Any modern distro (Ubuntu 22.04+ makes this even more cake)
Node.js v18.16+ (LTS) (Simply select your OS when you get it here!)
Git (optional but recommended on all platforms. Get it here!)